As edge computing continues to grow, running deep learning models like LSTMs on resource-constrained devices (TinyML) has become increasingly important. One of the key technologies enabling this is quantization—the process of compressing models by converting floating-point numbers to low-bit integers without significant loss in accuracy.
What is Quantization?
Quantization reduces the precision of weights and activations from 32-bit floating-point (float32) to 8-bit or 16-bit integers (int8/int16). This lowers the memory footprint and speeds up inference, especially on microcontrollers that lack a floating-point unit.
As described in Imagimob’s white paper, quantization can be applied to:
- Weights (e.g., LSTM kernel and recurrent matrices)
- Activations (inputs, outputs, and intermediate results)
How Quantized LSTM Inference Works
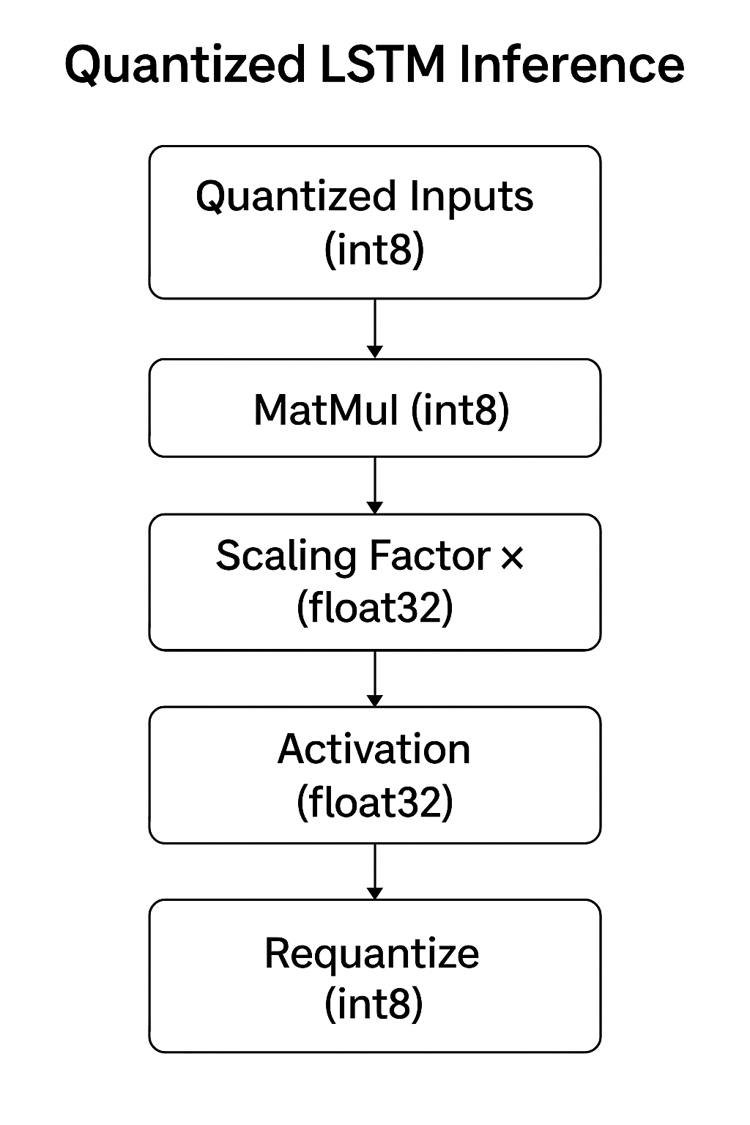
Since LSTMs involve recurrent steps, quantized inference requires special handling:
- Inputs and weights are converted to integers.
- Integer matrix multiplications are performed.
- A scaling factor restores the original range (e.g., 0.0039 × int8 = approx. float32).
- Non-linear activations like tanh or sigmoid may be computed in float or approximated.
- The output is re-quantized into int8 for the next step.
This process is repeated at each timestep. As noted here, preserving the temporal accuracy of LSTMs during quantization is key to maintaining performance in time-series tasks.
Does Accuracy Drop?
Yes—but not dramatically. Using techniques such as quantization-aware training (QAT) or post-training quantization (PTQ), models can adapt to integer-based calculations and still deliver useful predictions. Efficient Neural Networks for TinyML shows that smart initialization and careful layer-wise scaling are essential for stability.
Real-World Applications
Quantized LSTMs are already deployed in:
- Human activity recognition (e.g., wearable devices)
→ See Efficient HAR on edge - Industrial vibration or sensor anomaly detection
- Voice command detection in smart home devices
These applications benefit from reduced latency and power consumption, which is vital for battery-operated devices.
Conclusion
Quantization plays a pivotal role in enabling LSTM-based models on TinyML devices. As the field evolves, combining quantization with techniques like model pruning, knowledge distillation, and sparsity will further improve efficiency.
For a deeper dive, explore these excellent resources:
Leave a Reply